Security Week
New physics-based research suggests large language models could predict when their own answers are about to go wrong — a potential game changer for trust, risk, and security in AI-driven systems.
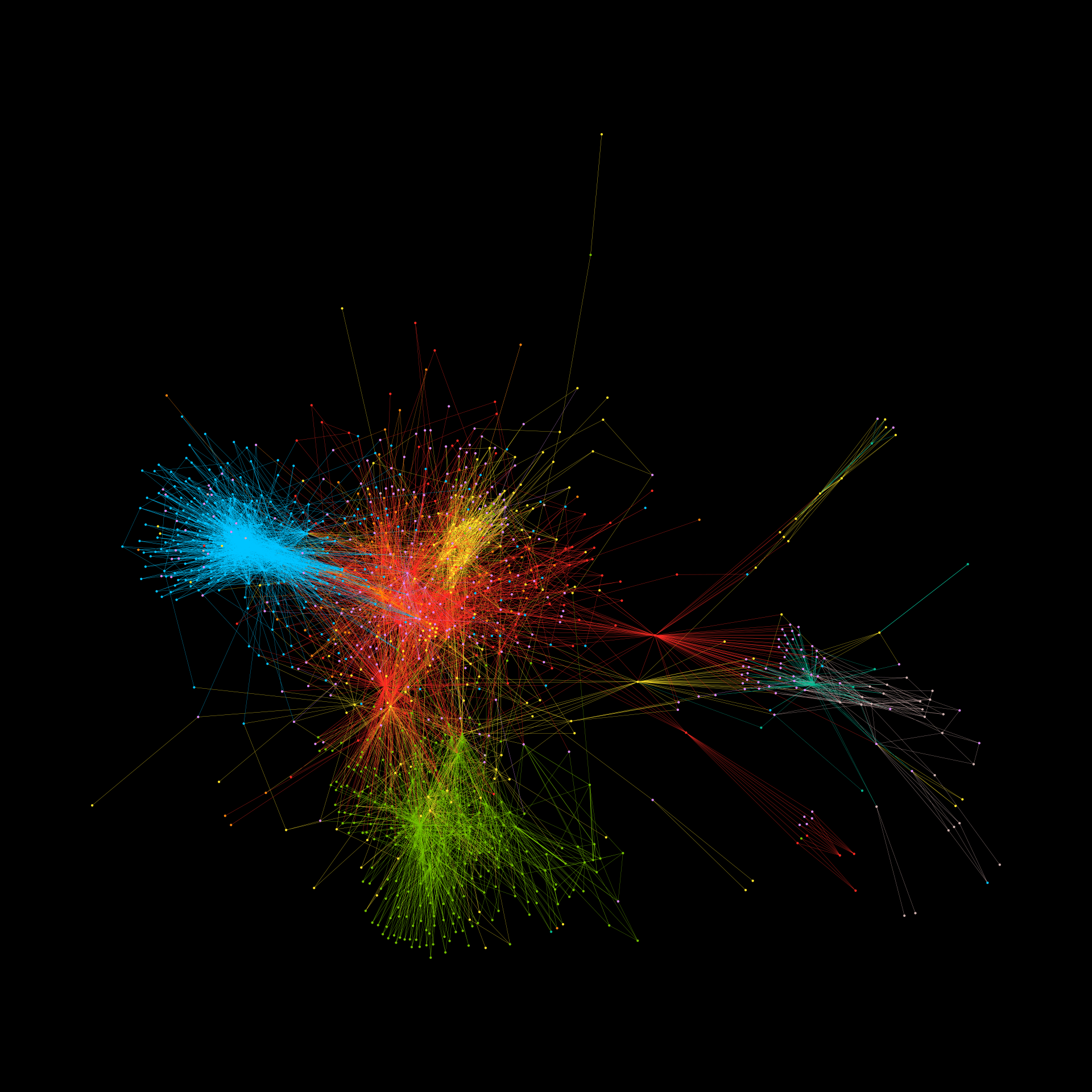
GWU-based group pioneering the new science of interacting humans, technology, and AI
Security Week
New physics-based research suggests large language models could predict when their own answers are about to go wrong — a potential game changer for trust, risk, and security in AI-driven systems.