SIAM News
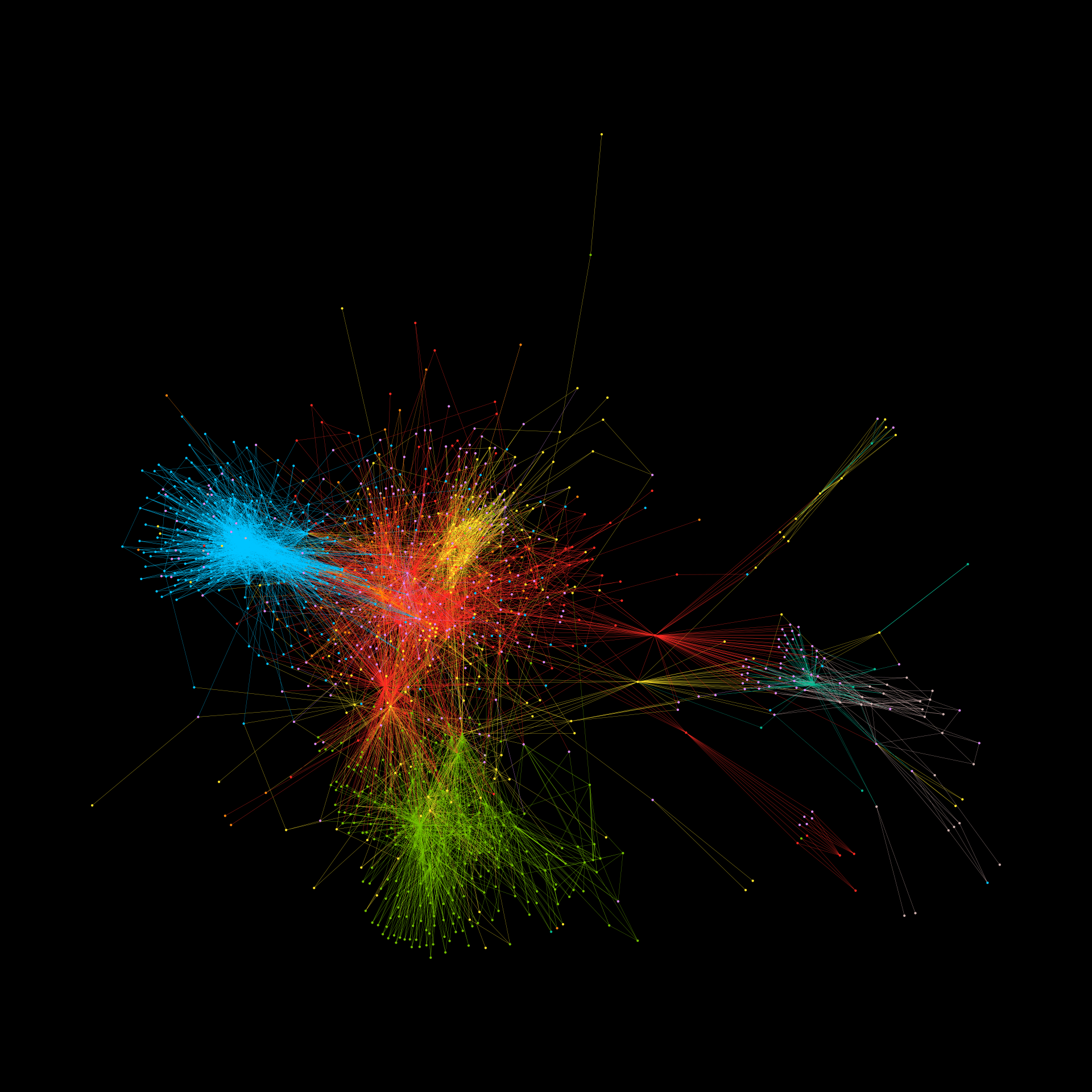
Tragic acts of terrorism—such as February’s mass stabbing in Austria by a 23-year-old Syrian asylum seeker who was allegedly radicalized online by the Islamic State —accentuate the dangers of radicalization via the internet. Terrorist organizations exploit popular social media platforms to advance their ideology-driven agendas through recruitment, fundraising, and the spread of propaganda — all of which ultimately causes severe harm in communities around the world. From a national security perspective, this drive towards radicalization raises pressing questions about our ability to monitor, quantify, understand, predict, and even mitigate such efforts before they materialize as tragedies.
Pedro Manrique and Neil Johnson
View article >>