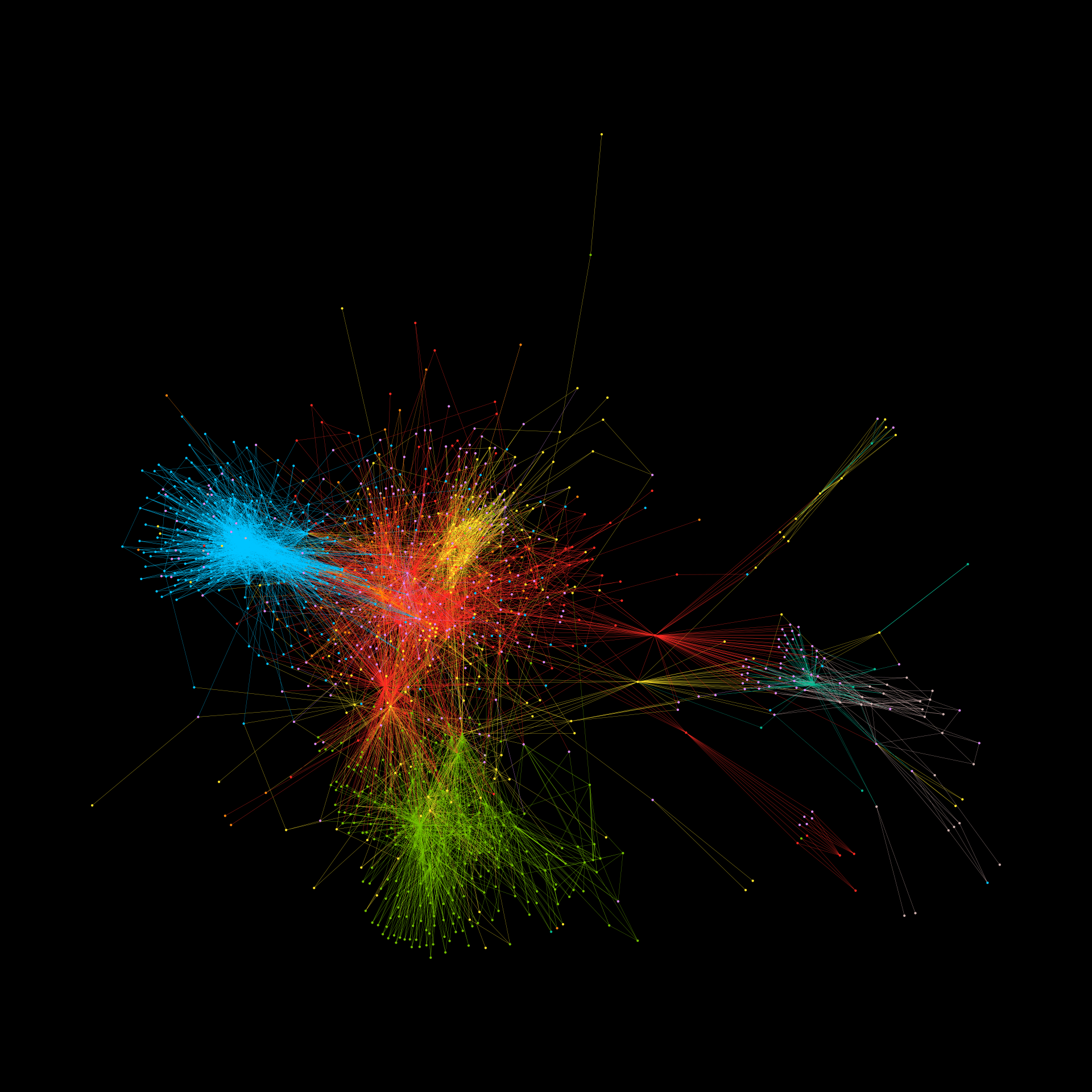
The Prompt Index
AI, particularly in the realm of language models like ChatGPT, has become an intriguing yet sometimes alarming part of our daily lives. With countless articles praising their benefits and cautioning their users, can we really trust AI to provide reliable information? Researchers Neil F. Johnson and Frank Yingjie Huo have recently delved into this question, highlighting a phenomenon they call the Jekyll-and-Hyde tipping point in AI behavior. Let’s dive into their findings and discover how this impacts our relationship with AI.